- The CiaoPP Program Processor »
- PART I - Using CiaoPP »
- Available abstract domains ▾
- aeq (abstract domain)
- def: definiteness (abstract domain)
- deftypes: defined types (based on termsd) (abstract domain)
- depth-k (abstract domain)
- eterms: types with lnewiden_el/4 (abstract domain)
- etermsvar: eterms with variables (abstract domain)
- frdef: freeness+definiteness (abstract domain)
- fr: minimal freeness (abstract domain)
- gr: simple groundness (abstract domain)
- lsign (abstract domain)
- lsigndiff (abstract domain)
- det: determinancy (abstract domain)
- nf: non-failure (abstract domain)
- Intervals (abstract domain)
ON THIS PAGE
Available abstract domains
This is an (incomplete) list of available domains. Check the CiaoPP sources and related bundles for a more complete list.Groundness and sharing
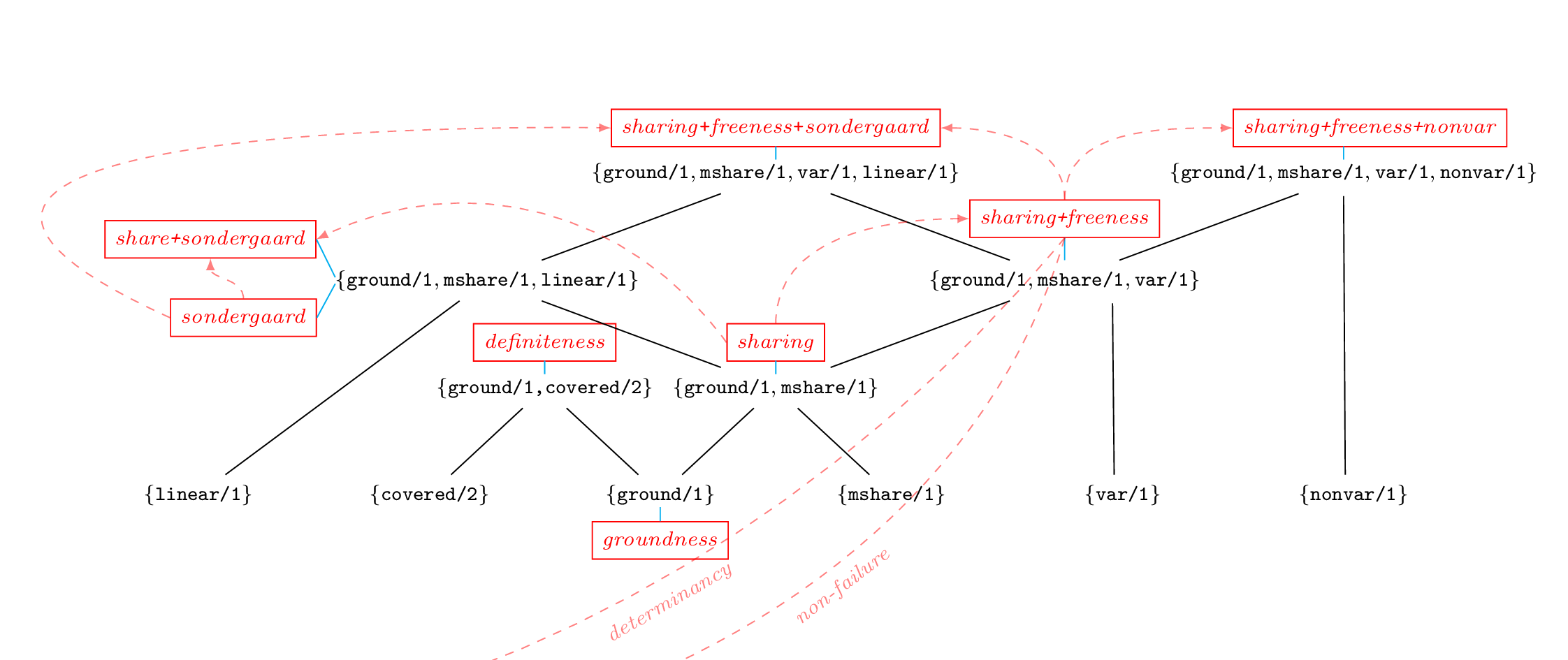
- gr (groudness) : {ground/1}
- tracks groundness in a very simple way (a toy example used in one of the tutorials).
- def (definiteness) : {ground/1,covered/2}
- tracks groundness dependencies, which improves the accuracy in inferring groundness.
- share (sharing) : {ground/1,mshare/1}
- tracks sharing among (sets of) variables [MH92], which gives a very accurate groundness inference, plus information on dependencies caused by unification.
- son (sondergaard) : {ground/1,mshare/1,linear/1}
- tracks sharing among pairs of variables, plus variables which are linear (see [Son86]).
- shareson (sharing+sondergaard) : {ground/1,mshare/1,linear/1}
- is a combination of the above two [CMB93], which may improve on the accuracy of any of them alone.
- shfr (sharing+freeness) : {ground/1,mshare/1,var/1}
- tracks sharing and variables which are free (see [MH91]).
- shfrson (sharing+freeness+sondergaard) : {ground/1,mshare/1,var/1,linear/1}
- is a combination of sharing+freeness and sondergaard.
- shfrnv (sharing+freeness+nonvar) : {ground/1,mshare/1,var/1,nonvar/1}
- augments sharing+freeness with knowledge on variables which are not free nor ground.
Alternative representation
- clique-set representation : {clique/1}
- A clique is a compact representation for a part of a sharing abstraction (mshare/1) which in fact does not convey any useful information. It is used to represent in a compact way such parts of sharing abstractions, and can also be used to lose precision in exchange for efficiency.
For instance, let V = {x, y, z, w} be the set of variables of interest. Consider the abstraction {x, xy, xyz, xz, y, yz, z, w}. We can see that there is no information available about the subset of variables C = {x,y,z} since any aliasing may be possible: there might be run-time variables shared by any pair of the three program variables, by the three of them, or not shared at all. Thus, we may define a more compact representation to group the powerset of C, i.e., the clique set. In our example, the clique that will convey the same information is simply the set C. It pays off to replace any set S of sharing groups, which is the proper powerset of the set of variables C, by including C as a clique. Moreover, the set S can be eliminated from the sharing set, since the presence of C in the clique set makes S redundant.
Available domains with this representation:
- share_clique (sharing+clique) : {ground/1,mshare/1,clique/1}
- sharefree_clique (sharing+freeness+clique) : {ground/1,mshare/1,var/1,clique/1}
- share_clique_def (sharing+clique+definiteness) : {ground/1,mshare/1,covered/2,clique/1}
- sharefree_clique_def (sharing+freeness+clique+definiteness) : {ground/1,mshare/1,var/1,covered/2,clique/1}
Term structure
- depthk (depth) : {instance/2}
- tracks the structure of the terms bound to the program variables during execution, up to a certain depth; the depth is fixed with the depth flag.
- path : {ground/1,mshare/1,var/1,=../2}
- tracks sharing among variables which occur within the terms bound to the program variables during execution; the occurrence of run-time variables within terms is tracked up to a certain depth, fixed with the depth flag.
- aeq : {ground/1,mshare/1,var/1,linear/1}
- tracks the structure of the terms bound to the program variables during execution plus the sharing among the run-time variables occurring in such terms, plus freeness and linearity. The depth of terms being tracked is set with the depth flag. Sharing can be selected between set-sharing or pair-sharing.
Types
Type analysis supports different degrees of precision. For example, with the flag type_precision with value defined, the analysis restricts the types to the finite domain of predefined types, i.e., the types defined by the user or in libraries, without generating new types. Another alternative is to use the normal analysis, i.e., creating new type definitions, but having only predefined types in the output. This is handled through the type_output flag.
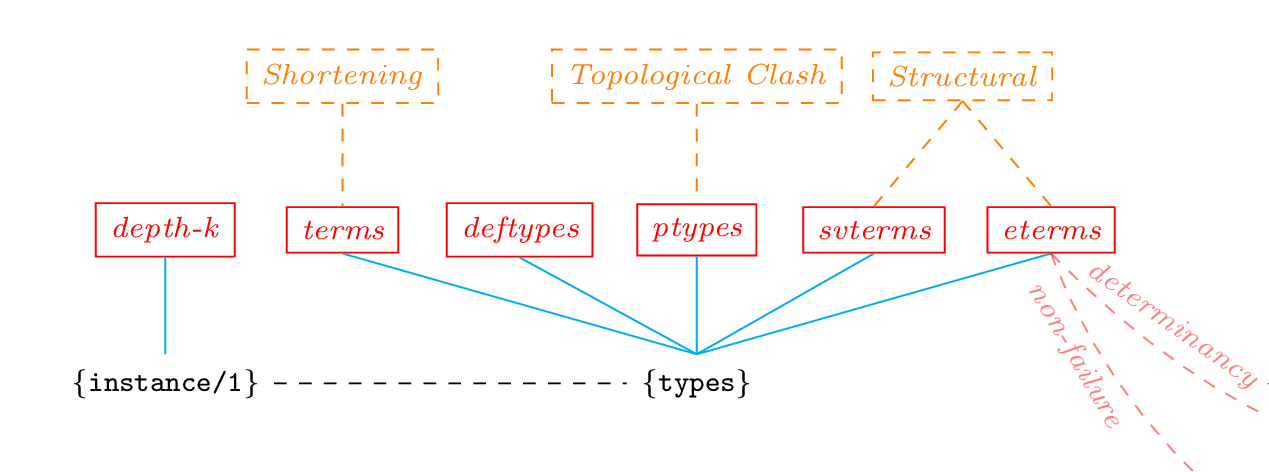
- eterms (eterms) : performs structural widening (see [VB02])
- .
Greater precision can be obtained evaluating builtins like is/2 abstractly: eterms includes a variant which allows evaluation of the types, which is governed by the type_eval flag.
- svterms
- implements the rigid types domain of [JB92].
- ptypes
- uses the topological clash widening operator (see [VHCL95]).
- deftypes
- implements types abstract domain (based on terms) that only includes library types, user-defined types and instances of parametric rules.
- terms
- uses shortening as the widening operator (see [GdW94]), in several fashions, which are selected via the depth flag; depth 0 meaning the use of restricted shortening [SG94].
Partial evaluation
Partial evaluation is performed during analysis when the local_control flag is set to other than off. Flag fixpoint must be set to di. Unfolding will take place while analyzing the program, therefore creating new patterns to analyze. The unfolding rule is governed by flag local_control (see transformation(codegen)).
For partial evaluation to take place, an analysis domain capable of tracking term structure should be used (e.g., eterms, pd, etc.). In particular:
- pd
- allows performing traditional partial evaluation but using instead abstract interpretation with specialized definitions [PAH04].
- pdb
- improves the precision of pd by detecting calls which cannot succeed, i.e., either loop or fail.
Note that these two analyses will not infer useful information on the program. They are intended only to enable (classical) partial evaluation.
Constraint domains
- fr (freeness) : {var/1,posdeps/1}
- [Dum94] determines variables which are not constraint to particular values in the constraint store in which they occur, and also keeps track of possible dependencies between program variables.
- frdef (freeness+definiteness) : {var/1,posdeps/1,covered/2}
- is a combination of freeness and definiteness, determining at the same time variables which are not constraint to particular values and variables which are constraint to a definite value.
- lsign
- [MS94] infers the signs of variables involved in linear constraints (and the possible number and form of such constraints).
- difflsign difflsign
- is a simplified variant of lsign.
Properties of the computation
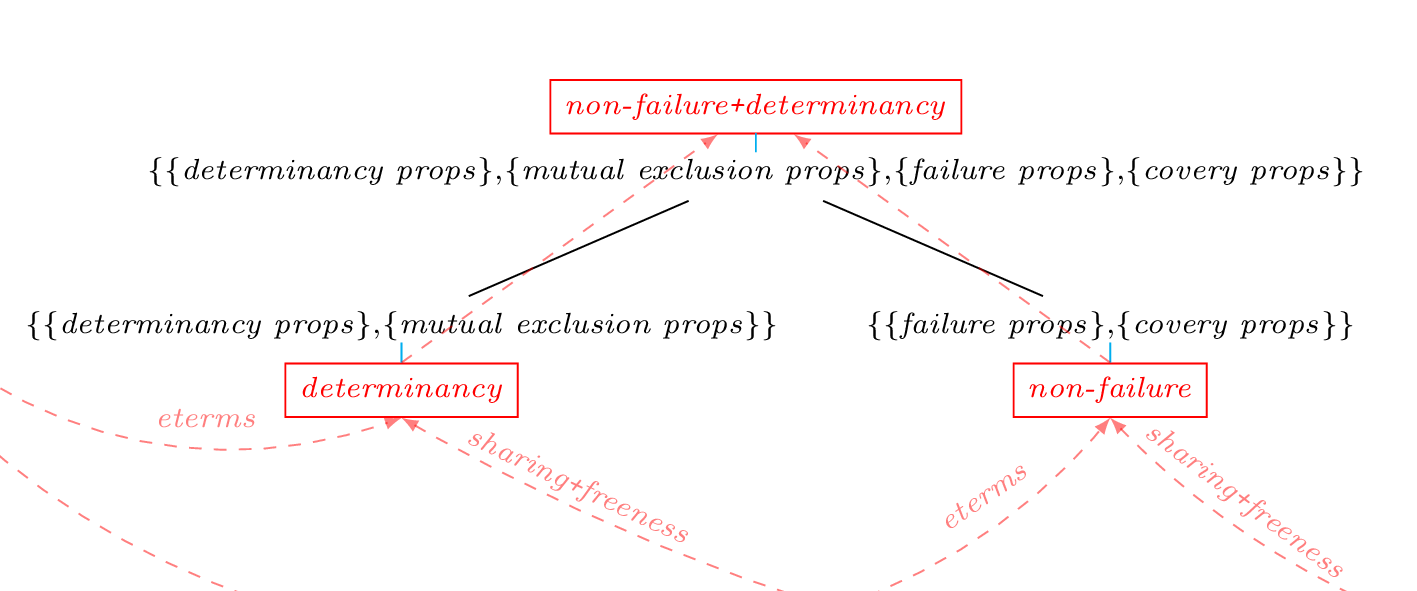
- det (determinancy) : {det/1,semidet/1,multi/1,nondet/1,mut_exclusive/1,not_mut_exclusive/1,possibly_not_mut_exclusive/1}
- detects procedures and goals that are deterministic (i.e. that produce at most one solution), or predicates whose clause tests are mutually exclusive (which implies that at most one of their clauses will succeed) even if they are not deterministic (because they call other predicates that can produce more than one solution).
- nfg : {not_fails/1,fails/1,possibly_fails/1,covered/1,not_covered/1,possibly_not_covered/1}
- was the first non-failure analysis algorithm (which had a specific fixpoint) implemented in CiaoPP. It detects procedures that can be guaranteed not to fail (i.e., to produce at least one solution or not to terminate). It is a mono-variant non-failure analysis, in the sense that it infers non-failure information for only a call pattern per predicate [DLGH97].
- nf (non-failure) : {not_fails/1,fails/1,possibly_fails/1,covered/1,not_covered/1,possibly_not_covered/1}
- (originated as a re-cast of the nfg) detects procedures and goals that can be guaranteed not to fail and is able to infer separate non-failure information for different call patterns [BLGH04].
- nfdet (non-failure+determinancy)
- : merges the non-failure and determinancy abstract domains into a combined domain.
- seff : {sideff/2}
- marks predicates as having side-effects or not.
Size of terms
Size analysis yields functions which give bounds on the size of output data of procedures as a function of the size of the input data. The size can be expressed in various measures, e.g., term-size, term-depth, list-length, integer-value, etc.
- size_ub : {size_ub/2}
- infers upper bounds on the size of terms.
- size_lb : {size_lb/2}
- infers lower bounds on the size of terms.
- size_ualb : {size_lb/2,size_ub/2}
- infers both upper and lower bounds on the size of terms.
- size_o : {size_o/2}
- gives (worst case) complexity orders for term size functions (i.e. big O).
Number of resolution steps of the computation
Cost (steps) analysis yields functions which give bounds on the cost (expressed in the number of resolution steps) of procedures as a function of the size of their input data.
- steps_ub : {steps_ub/2}
- infers upper bounds on the number of resolution steps. Incorporates a modified version of the CASLOG [DL93] system, so that CiaoPP analyzers are used to supply automatically the information about modes, types, and size measures needed by the CASLOG system.
- steps_lb : {steps_lb/2}
- infers lower bounds on the number of resolution steps. Implements the analysis described in [DLGHL97].
- steps_ualb : {steps_lb/2,steps_ub/2}
- infers both upper and lower bounds on the number of resolution steps.
- steps_o : {steps_o/2}
- gives (worst case) complexity orders for cost functions (i.e. big O).
Resources abstract domains
Resources abstract domains aim at inferring the cost of executing programs, in terms of a given resource, such as the traditional execution steps, time or memory, and, more recently energy consumption or user defined resources.- resources : {cost/4}
- res_plai : {cardinality/3, rsize/2}
Other numeric abstract domains
- polyhedra : {constraint/1}
- allows us to discover linear arithmetic constraints (equalities and inequalities) among variables of a program.