WebDB provides a way to create and customize a
Relational Database and/or a
WWW interface to access it.
WebDB provides a simple WWW interface based on
HTML forms which allows the user to access the data stored in any database, local to
WebDB itself or remote.
In the first case, the tables are designed according to the definition of filebased persistent predicates, using the library
persdb [GCH98] and are maintained directly by
WebDB, allowing the system administrator to create, destroy or edit the tables. In the second case, the data is stored in remote SQL databases, so that
WebDB just provides an interface to them through the primitives espeficied in the library
persdb_sql [CCG98].
As we will see, the information can be accessed in two different ways. We could say that
WebDB provides a
single table interface and a
multitable interface.
Through the first way, the interface to access a table is created automatically on every access. This is achieved by defining each table field according to an html_format type, which is translated by a template into the right HTML input type for the given field, for example, a checkbox, an input box or a textarea.
The system administrator can add new types and define tables according to them. Of course,
WebDB provides an interface to develope this task in an automatic way.
The multitable interface or, as we will see in further sections, the complex query option provides an interface to make queries over a database view in both, Prolog or SQL syntax, by offering a window where the user can write them.
Settings in
WebDB are kept in
configuration files, and are customizable, as well as types and templates. The system administrator can customize them on line, without needing to stop the system, through the interface provided by the application itself.
As mentioned above, the data
WebDB operates on can be local or located at remote SQL databases. In both cases,
WebDB provides a WWW interface to access it in a transparent and comfortable way.
These two kinds of data storage are based upon the same concept: Persistent Predicates. The idea is that whatever changes might have been done on one of these predicates survive across executions. This way, no matter whether the system stops, or even crashes, we will always have a consistent state of the predicate, which is quite an useful thing if we want to implement a database. If Prolog is halted and restarted, the predicate the new Prolog process sees is right in the state it was in the very moment the old process was halted, provided that no changes to the external storage were done in the meantime by other processes or the user himself.
Actually, there are two different implementations of persistent predicates:
WebDB implements the tables located on remote SQL databases.
The first method can be used for storing smaller amounts of data that we will call
local data. In
WebDB this kind of persistent predicates are also used to manage most of the internal information the system needs to handle the operations the services it provides resemble. In a wider context, e.g. the Prolog world, it seems an easy and efficient way to achieve persistence, saving the state of the predicates through executions, which, up to now, is something Prolog systems where quite lack of.
The second method provides a very high-level natural way to access, from a Prolog program, larger amounts of data in SQL database relations. According to this method, persistent predicates are linked to tables in external databases so that the predicates actually reside in such tables. These tables are seen from the Prolog side as ordinary predicates.
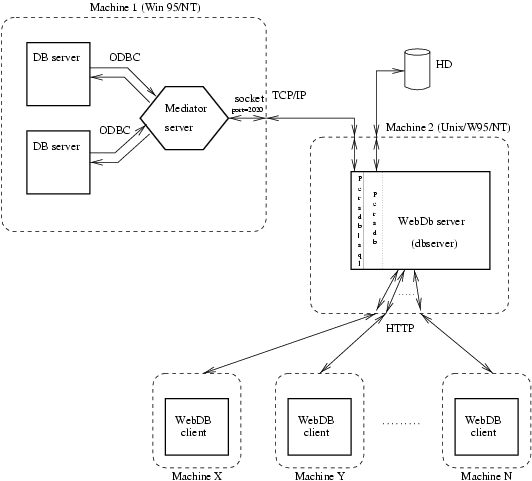
In the next figure, we can appreciate the interaction between
WebDB and these two kinds of persistent predicates as well as the system's architecture:
As we can see in the figure, the
WebDB server provides its services through the WWW. These services basically consist of an interface to query the database and, in the case of the system administrator, manage the system.
This part of the
WebDB documentation is aimed to describe its database server,
dbserver, which provides the users with services to access a given database. This server has been developed as a
CIAO prolog
active module and is basically an executable which publishes its IP address in order to allow client programs to use its services. Client programs are invoked with the CGI protocol by the web server and connect to the active module to request server actions.
This server also uses the capabilities provided by the filebased persistent predicates to manage the multiple aspects of the database it is bound to, for example, to keep the current state of a search or the current description and type of a given table, or even the text messages which are output as a result of any interaction with the system.
In order to make the database accessible from the web, the dbserver is launched through the CGI
startdbserver.cgi and its standard error output is redirected to a file called
dbserver.log, located on the
private directory. This way, any misbehaviour or problem occurred will be registered and, therefore, solved more easily. The steps the dbserver carries out at this point follow:
First of all, the dbserver processes the contents of the file
dbserver_ini.pl. This file is created during the installation and contains important data relative to the directories of the database and its URLs.
The next step is to read the configuration files for the database. Database customization basically lies on these files, which contain information regarding the
html_format
types and
templates and their translation into
PiLLoW terms, as well as information about the searches lifetime, the translation between
html_format and SQL
types and the remote SQL databases the system is bound to.
Once all this information has been processed, dbserver can start the processing of data regarding the database tables. So, dbserver enables for future queries both kinds of tables, local tables based upon filebased persistent predicates and remote tables based upon SQL-based persistent predicates.
The next step is to start the statistics procedure by resetting the date of initialization for the dbserver. This information can be accessed through the service provided by the option
status lying on the maintenance front page .
Finally, if necessary, dbserver generates a maintenance front page which is the first part of the manager interface, and initializes all those other persistent predicates embedded in the system which are used for inner tasks such as keeping a trace of the current state of queries and the text of the user interface messages.
The
WebDB interface is aimed to be an easy and straightforward way to query and manage a database. As we can see in the figure, this interface is composed by several stages. Each one offers the right interface for a given service, many of them only allowed to the user administrator.
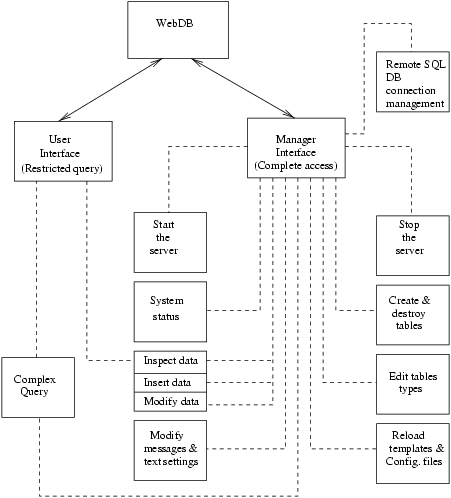
Let's concentrate on the manager interface as the common user interface is quite simple and consists of a restricted version of the manager search interface.
The first stage of the manager or administrator interface is a maintenance front page where the following options are provided:
WebDB to remote SQL databases and unlink it from a previously added one. Through this interface, it is possible to collect the information
WebDB needs in order to accessing the tables of a given database. Besides, it provides information about the remote SQL databases the system is already linked to.
Additional information must be given about the fourth and fifth options:
Once the user has decided on which table to operate on, this option displays the system consult interface. Through this interface the user can choose which operation to carry out.
Initially, the system administrator, can choose among the following operations:
If the user is not an authorized client, the operations allowed will only be Search, Overview and Full search which, in this case, will not allow the user to edit the results of a previous query.
Note that when any query is made over a database table, the information written into the form fields is taken as prolog terms. This way, any empty field of the form is translated into a free variable and therefore will unify all the corresponding arguments of the given table.
Besides,
WebDB provides three different search modes:
This option is fully available for both authorised and not authorised clients. As mentioned above, it provides an interface to query the database in Prolog and SQL syntax. It is necessary to select the view the tables involved in the query lay on.
When only local tables are involved in the query, the predicates allowed in this environment are restricted in order to avoid any eventual misuse. This set of allowed predicates can be classified in the next categories: arithmetic and relational operators, connectors (i.e. ',' and ';') and the tables of the database itself.
On the other hand, in the case of tables belonging to remote SQL databases, it is quite recommendable to control which views are to be accessible for the system users and with which rights in order to prevent the SQL tables from being manipulated unduly.
As an on-line guide for the user, this option displays a list of the tables the database consists of. This includes information about the arity of the tables, the physical database where they are located and the types of their fields.
There are three possible answers for a complex query:
This part of the
WebDB documentation is aimed to describe the CGI clients which are included by default with the distribution of
WebDB and form the interface described in the previous section.
These clients use the services provided by the server to query the database or manage the system. From this point on, the number of clients added only depends on the system administrator and the number and nature of the services required by any specific case.
Each client is firmly related to the services provided by the server. In most cases, this relation is an injective application, as we can see:
get_relationsdb
consultdb
get_relationsdb
consultdb
complex_query
create_destroy_table
select_table_to_edit
edit_table
consultdboptions
dbtemplates
status
connect_to_DB
dying,
die
Going back to the first figure, we can see that, in fact, every component of
WebDB can be located on distant hosts on the WWW, as they get through with one another using the
HTTP protocol. This leaves an open door for distributed databases due to its interconnectivity.
WebDB's customizability lies on a series of files, file based persistent predicates and predicates which constitute a system of types and templates in order to generate the HTML representation of every table. In the nex figure we can appreciate the interaction of each of these components with one another and with dbserver.
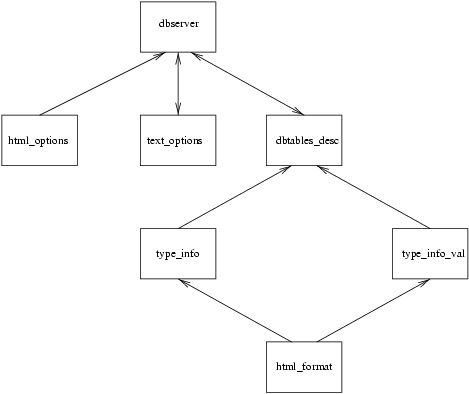
Let's describe these components:
WebDB using the operations Create/Destroy Tables and Edit Tables Types of the maintenance front page.
DBDATADESC/db_desc/dbserver:dbtables_desc-2.pl. This entry must be written in the following format:
'dbserver:dbtables_desc'( <<Table_name>>( <<Type 1>>(<<Field description 1>>, <<Length 1>>), <<Type 2>>(<<Field description 2>>, <<Length 2>>), <<Type n>>(<<Field description n>>, <<Length n>>)), <<Situation>>, <<Creation Date>>).Besides, it is possible to link the tables laying in an SQL remote database through the operation Remote SQL Databases Connection Management.
WebDB distribution includes an example of these types and templates for a given database and surely the best way to make a new one is by pattern matching.
Each of these types need to have their corresponding entry in the file
html_format located on the directory
DBDATADESC/db_types which will be described next.
In every case, the second argument of
dbserver:dbtables_desc/3 points out whether the table is local, by setting that field to the value `local', or remote, by writing the identifier of the view for the SQL database. That kind of identifier is defined in the filebased persistent predicate
sql_location/2 which, just like the
DBDATADESC/db_types/html2sql.pl, is described in the next section (Defining SQL remote Databases).
type_info/3 and
type_val_info/4 are used to obtain the translation between a type defined for a field in dbtables_desc and its corresponding template of html_format, which is the component to be described next.
type_info is used to get the html_format template of a table field and its description before making any query and, on the other hand,
type_val_info gets the contents of a table field after the query has been made.
PiLLoW in a transparent way. An entry of html_format can be equivalent to a large piece of
PiLLoW code and, therefore, it contributes to make things simpler and more customizable.
This is fundamentally achieved thanks to the library
persdb_sql which provides and interface to remote SQL databases located on Win95/NT machines. In order to use the facilities provided by that library,
WebDB needs the predicate
sql_location/2 and the file
html2sql.pl, described next:
sql_location.pl is an SQL based persistent predicate that contains entries
WebDB uses to define the fact
sql_persistent_location/2 (see the documentation of
persdb_sql [CCG98]) for each remote SQL database view linked to
WebDB.
html2sql.pl contains instances of the predicate html2sql/2 which provide the translation between the macros defined in html_format and their equivalent SQL types.
sql2html.pl, in the opposite direction, allows to find the right html_dormat representation type for a given SQL type.
Go to the first, previous, next, last section, table of contents.